![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~

BMJ小小統計問題(144):Uncertainty in sample estimates: standard error [樣本估計值的不確定性:標準誤差]
Cite this as: BMJ 2015;350:h1914
https://www.bmj.com/content/350/bmj.h1914
前言
本文與上周主題相同,均為講解樣本估計值的不確定性,著重於說明標準誤差(SE)的概念。樣本平均值是母群體參數的估計值,但由於樣本是從母群體中抽取的,因此樣本平均值與母群體參數間存在著不確定性。標準誤差是衡量這種不確定性的一種方法,其反映樣本平均值作為母群體參數估計值的準確性。文章指出,增加樣本數可以減小標準誤差,從而提高估計值的準確性。此外,信賴區間作為母群體參數的區間估計值,能夠量化樣本平均值的不確定性,並提供統計假設檢定。這些在統計學領域,都是作為基石的概念。是學習統計專業必須了解的知識。
相關概念課程可見於【eB02-小白的醫學統計必修課(上)】,講解醫學統計學核心概念進行系統性理解,專治統計不全症;以及,最實用的醫學實戰統計課程【eB02-小白的醫學統計必修課(下)】。另於官網最新消息公告公司直播課程,包括國外公開醫學資料庫、文獻管理利器、統合分析文獻解析等等;統計或研究課程/工作坊請至官網課程報名一覽,或是訂閱公司Google行事曆與最新消息。
有任何問題可至本公司官方line:@medatatw 洽詢。感謝眾多朋友兩年多來的一路陪伴,隨著匯東華三周年慶腳步漸近,越發感謝。Hope u enjoy it
路徑:匯東華官網/學習專區/BMJ小小統計問題列表
本期相關主題:
#第11題:What is sampling error
#第80題:Standard deviation versus standard error
#第90題:Standard deviation or the standard error of the mean
#第103題:Sampling distributions
#第136題:Standard error of the mean
#第134題:A comparison of sampling error and standard error
#第143題:Uncertainty in sample estimates: standard error
#第144題:Uncertainty in sample estimates: standard error [本期]
✨線上課程提供【流行病學】與【生物統計學】系列https://medata.teaches.cc/
✨匯東華會員制詳情:https://reurl.cc/NyjNMx
課程介紹與報名資訊:https://reurl.cc/EoRxpg
線上課程學院:https://medata.teaches.cc/
-----
問題:
一項隨機對照試驗調查共同護理肥胖管理計畫對肥胖兒童BMI和相關結果的影響。介入措施包括對兒童肥胖症進行全科監測,然後在初級和三級醫療機構採用共用護理模式進行肥胖症管理。
介入措施為期一年。對照治療包括 “常規護理”。參與者為 3-10 歲的兒童,他們的體重指數高於其年齡和性別的第 95 百分位數。研究地點在澳大利亞墨爾本。共有 118 名兒童通過診所被招募,並被隨機分配到介入組(62 名)或對照組(56 名)[1]。
主要結果是BMI。BMI 的測量值被轉換為 z 分數。追蹤結束時,介入組的平均體重指數 z 值小於對照組,但差異不顯著(2.0(標準差 0.5)v 2.0(0.4);調整後的平均差異為-0.05,95% 信賴區間為-0.14 至 0.03;P=0.2)。在任何次要結果中,包括體脂率、腰圍、體力活動、飲食品質和與健康相關的生活品質,均未發現有明顯差異的證據。結論為,初級和三級護理管理的共同護理模式對肥胖兒童的BMI和相關結果沒有影響。
下列敘述何者正確?
a) 樣本估計容易出現抽樣誤差
b) 從母群體中抽取樣本會產生抽樣誤差
c) 抽樣誤差通過追蹤時平均體重指數 z 分數的標準誤差來量化
d) 一般來說,抽樣誤差會隨著樣本數的增加而減少
答案
以上皆是。
詳細說明:
該試驗旨在確定共同護理肥胖管理計畫對肥胖兒童BMI和相關結果的影響。主要結果是BMI。兒童的成長模式會隨著年齡的增長而發生變化,男孩和女孩的生長模式也不盡相同。因此,為了能夠對不同年齡和性別的兒童進行比較,BMI 測量值通過 z 評分進行標準化處理 [2]。每個治療組追蹤時的樣本平均 BMI z 評分是對該治療的母群體參數的估計,即若母群體中的所有兒童都接受該特定治療,則會出現的平均 BMI z 評分。此外,在 12 個月時觀察到的治療組間平均 BMI z 分數的差異是對不同治療組間平均 BMI z 分數差異的母群體參數之估計。
抽樣是為了推論介入與對照治療的效果。樣本只是從母群體中抽取的眾多可能樣本之一。抽樣的性質為,可能影響某人參加或退出試驗的人口特徵和其他特徵,在樣本中不可能與母群體相同。因此,根據樣本估計值推論母群體參數存在不確定性。統計學的目的即為量化此類推論之不確定性。雖然我們希望樣本估計值的大小與母群體參數相似,但它們不可能完全相同。因此,樣本估計值容易出現抽樣誤差(a正確)。
抽樣誤差是指樣本估計值與母群體參數間的大小差異。統計意義上的 “誤差 ”一詞並非意指抽樣時犯了錯誤。誤差是指樣本值作為母群體參數估計值的不準確性--是獲得樣本後進行推論的直接結果。使用所得樣本對對母群體進行推論的直接結果(b正確)。
母群體參數是未知的。因此,抽樣誤差為一理論概念。抽樣誤差使用平均值的標準誤差來量化(c正確)。平均值的標準誤差 (SEM) 有時簡稱為標準誤差 (SE),是從樣本資料所得。一般來說,標準誤差越大,樣本平均數作為母群體參數的估計值就越不準確。在本研究中,每個治療組追蹤時的平均體重指數 z 值是該治療組的母群體參數估計值。每個治療組的樣本估計值的標準誤差雖然沒有列出,但卻是用 12 個月時 BMI z 分數的標準差除以各治療組參與者人數的平方根得出的。因此,隨著樣本數的增加,標準誤差一般會減小,代表樣本對母群體參數的估計更加準確。平均值的標準誤差和標準差經常被混淆 [3]。BMI z 分數的標準差並不能衡量抽樣誤差,只能說明樣本中分數測量的分佈情況。
平均值的標準誤差和抽樣誤差經常被混淆。抽樣誤差是一個理論概念,由標準誤差量化。治療組 BMI z 評分均值的標準誤差本身用途有限。僅被用來推導信賴區間--一個量化樣本平均值作為母群體參數估計值的不確定性之數值範圍。然而,在比較介入治療與對照治療時,提出治療組間平均 BMI z 評分差異的信賴區間,而不是比較各治療組平均 BMI z 評分的信賴區間,是一良好的做法,也更有參考價值 [4]。雖然內文沒有提出,但得出治療組間 12 個月平均 BMI z 評分差異的標準誤差;被用來計算追蹤時治療組間平均 BMI z 評分差異母群體參數的 95% 信賴區間。
一般而言,隨著樣本數的增加並接近母群體總數,樣本將更準確地代表母群體。隨著樣本數的增加,樣本估計值的大小會更接近母群體參數,從而減少抽樣誤差(d正確)。如上所述,抽樣誤差用平均值的標準誤差來量化;隨著樣本數的增加,標準誤差一般會減小,反映出抽樣誤差的減少。此外,若在增加樣本數的同時,招募參與者的方法也能產生具有母群體代表性的樣本,則抽樣誤差就會得到控制[5]。因此,很難量化兒童樣本在母群體中的代表性,但如果採用分層分組抽樣等其他招募方法,樣本的代表性會更強。
Reference:
[1] Wake M, Lycett K, Clifford SA, et al. Shared care obesity management in 3-10 year old children: 12 month outcomes of HopSCOTCH randomised trial. BMJ 2013;346:f3092.
[2] Sedgwick P. Standardising outcome measures using z scores. BMJ 2014;349:g5878.
[3] Sedgwick P. Standard deviation or the standard error of the mean. BMJ 2015;350:h831.
[4] Sedgwick P. Randomised controlled trials: inferring significance of treatment effects based on confidence intervals. BMJ 2014;349:g5196.
[5] Sedgwick P. Convenience sampling. BMJ 2013;347:f6304.
[6] Sedgwick P. Stratified cluster sampling. BMJ 2013;347:f7016.
#匯東華 #BMJ統計問題 #醫學統計 #抽樣誤差 #假設檢定 #標準誤差 #95%信賴區間 #假設檢定

數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
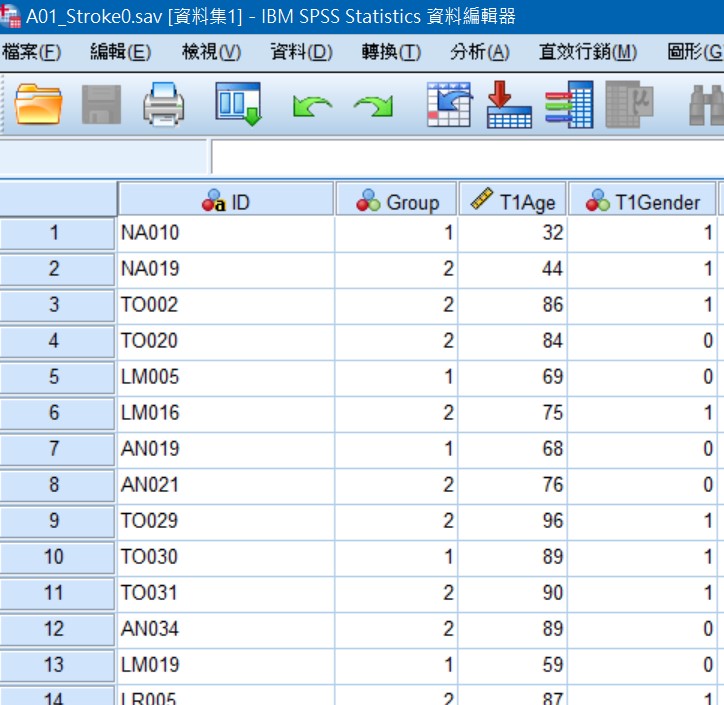
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖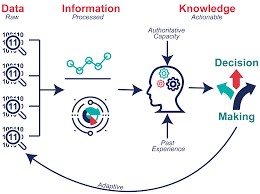

教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk

計畫撰寫與統計諮詢


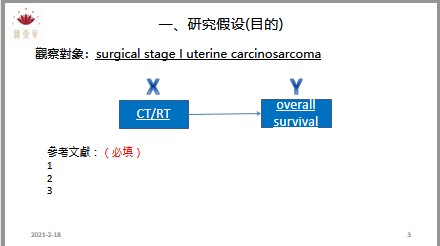
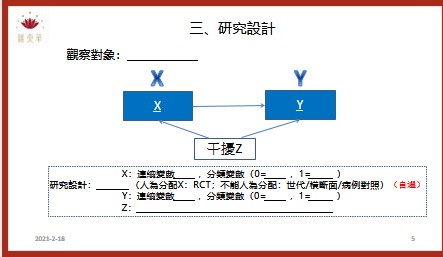
為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。