![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~

BMJ小小統計問題(99):Meta-analyses IV
Cite this as: BMJ 2011;342:d540
https://www.bmj.com/content/342/bmj.d540.full
前言
2周年慶倒數!第99期了,然後是100期!剛好是二週年那周!真是很巧!7/19(三)匯東華統計顧問有限公司成立二周年。屆時公司將公休一日,慶祝匯東華誕辰,好好休養生息。原來百期跟二年,走著走著也就到了。
本期主要介紹統合分析之結局變數為連續性時的說明,可與#第74題:Meta-analyses: standardised mean differences (統合分析:標準化平均值差異)一起閱讀。特別需要注意結局變數為二分類以及連續性時的無效線垂直於何值。看過幾篇meta-analysis研究,核心森林圖的無效線垂直的對應的數字是錯的。
本月課程資訊下方為BMJ小小統計問題目前已有之meta-analyses相關主題,合輯收錄於「匯東華官網/學習專區/精選文獻與學習資源」,於100期結束後,會由本人重新彙整為meta-analysis之合輯。 Hope u enjoy it
✅7/22(六)「A01-1-SPSS零基礎入門統計課程」、7/23(日)「A03-Logistic regression」(早)+「A02-存活分析」(午)招生中!
“帶你從零基礎開始,一次學會如何使用SPSS從零開始、單變項到多變項分析。”
✅7/26(三)AI01-探索ChatGPT+ AI02-活用ChatGPT [本班已額滿!感謝支持]
✅7/29(六)「WS1-統合分析研究工作坊:基礎班」、7/30(日)「WS2-統合分析研究工作坊:實戰班」招生中!
“帶你從零基礎開始,由淺入深進入系統性綜述/統合分析的世界。有理論,更有實務。”
課程介紹與報名:https://reurl.cc/EoRxpg
#第40題:統合分析:如何解讀漏斗圖 (Meta-analyses: how to read a funnel plot)
#第41題:統合分析:報告偏差的檢定 (Meta-analysis: testing for reporting bias)
#第47題:統合分析:異質性和子群體分析 (Meta-analyses: heterogeneity and subgroup analysis)
#第70題:Meta-analyses: tests of heterogeneity (統合分析:檢定異質性)
#第71題:Meta-analyses: what is heterogeneity? (統合分析:何謂異質性)
#第72題:How to read a forest plot (如何解讀森林圖)
#第73題:How to read a forest plot in a meta-analysis (如何解讀統合分析森林圖)
#第74題:Meta-analyses: standardised mean differences (統合分析:標準化平均值差異)
#第75題:Meta-analyses: sources of bias (統合分析:偏差來源)
#第76題:What is publication bias in a meta-analysis? (何謂統合分析的出版偏差?)
#第77題:How to read a funnel plot in a meta-analysis? (如何解讀統合分析漏斗圖?)
#第96題:Meta-analyses I (統合分析I)
#第97題:Meta-analyses II (統合分析II)
#第98題:Meta-analyses III (統合分析III)
#第99題:Meta-analyses IV (統合分析IV)
------之後主題-----
#第100題:Meta-analyses V (統合分析V)
-----RR相關概念說明-----
#第42題:什麼是相對危險性? (Relative risks?)
#第44題:絕對風險與相對風險 (Absolute and relative risks)
#第45題:相對風險與信賴區間 (Relative risks and confidence intervals)
#第46題:何謂風險 (What is risks?)
問題
研究人員對抗肥胖藥物在減肥和改善健康狀況方面的長期療效進行統合分析[1]。僅包括在成人(18歲以上)中使用一年或更長時間的雙盲隨機安慰劑對照試驗。
主要結局是體重從基線的變化。對每種確定的藥物進行單獨的統合分析。共發現14項orlistat試驗,統合分析結果在森林圖中呈現。orlistat在減肥方面比安慰劑更有效;與安慰劑相比,體重減輕的平均差異為2.87 kg(95%信賴區間2.53至3.21)。

(來源:Rucker D, Raj P, Li S, Curioni C, Lau D. Long term pharmacotherapy for obesity and overweight: Updated meta-analysis. BMJ (Clinical research ed). 01/01 2008;335:1194-9. doi:10.1136/bmj.39385.413113.25 )
下列敘述何者正確?
a)無效線將是穿過森林圖為”1”的垂直線
b)負加權平均差表示安慰劑在減肥方面比orlistat更有效
c)樣本估計值間存在統計學異質性
d) orlistat組體重的總估計變化與安慰劑組在5%的顯著性水準上顯著不同
e)可得出結論,安慰劑在減肥方面是無效的
答案:
d正確,其餘錯誤
詳細說明
Orlistat與安慰劑的比較是通過計算組間主要結局的基線體重變化之差異。零差異表明orlistat和安慰劑的平均體重變化是相等的。因此,在森林圖上,無效線會垂直穿過”0“(a錯誤)。先前的問題為隨機對照試驗的統合分析,主要結果是二元的[2-4]。RR用於比較組間發生結果的危險度。在此情況下,RR為1.0表示兩組的風險相等,因此在森林圖上無效線將垂直穿過1.0。
對於每個試驗中的orlistat組和安慰劑組,樣本數,加上基線體重變化的平均值和標準差顯示在森林圖左側。樣本均值的差異計算為orlistat減去安慰劑,並表示為“加權平均差異” (weighted mean difference)。在“權重(%)” (Weight (%))列中顯示每種差異的權重百分比,即每次試驗對總效果的影響。每個試驗的百分比權重由其樣本估計值的精確度決定;那些對總平均差異估計更準確的試驗具有更大的權重。在所有試驗中,orlistat和安慰劑的樣本平均值均為陰性;因此,每組參與者的平均體重都比基線有所下降。在所有的試驗中,orlistat的減肥效果更大,所以orlistat和安慰劑的平均差異為負數。樣本均值的負差異有利於orlistat,並呈現在無效果線左側的森林圖上(b錯誤)。
上周問題說明統合分析如何結合異質性的統計檢驗來評估樣本估計值間的差異程度[4]。Orlistat統合分析異質性統計檢定之P值為0.61,大於0.05(傳統的臨界顯著水準),Higgins I2統計量為零。因此,沒有證據顯示樣本估計值間存在異質性(c錯誤)。由於樣本估計值間不存在異質性,因此可以使用固定效果模型來推導總效果量估計值,而非隨機效果模型,如森林圖頂部所示。然而,若異質性不存在,則隨機效果模型與固定效果模型會有相同的總效果量估計值。
orlistat和安慰劑(orlistat減去安慰劑)間體重變化的平均差異的總效果估計值為- 2.87 kg(95%信賴區間為- 3.21至- 2.53)。因此,服用orlistat比服用安慰劑平均多減輕2.87公斤體重。95%信賴區間不包括平均差為零。若包括零則表示orlistat和安慰劑在平均體重變化方面沒有差異。因此,本分析結果顯示,orlistat和安慰劑在平均體重變化方面存在5%顯著水準的統計學差異(d正確)。總效果的統計假設檢定結果證實此發現-p <0.001。
雖然orlistat和安慰劑間的體重變化的平均差異在5%的顯著水準上是顯著的,而且orlistat更受青睞,但並不意味安慰劑沒有產生體重減輕(e錯誤)。在每個試驗中,對於每一個安慰劑組,平均體重變化是負的,顯示平均體重是減輕的。
Reference
- Rucker D, Padwal R, Li SK, Curioni C, Lau DCW. Long term pharmacotherapy for obesity and overweight: updated meta-analysis. BMJ2007;335:1194.
- Sedgwick P. Meta-analyses I. BMJ2011;342:d45.
- Sedgwick P. Meta-analyses II. BMJ2011;342:d229.
- Sedgwick P. Meta-analyses III. BMJ2011;342:d244.
# BMJ Statistics Questions Endgames #Meta-analysis #Heterogeneity #Cochran’s Q test #Higgins’s I2 #Forest plot #Standardised mean differences

數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。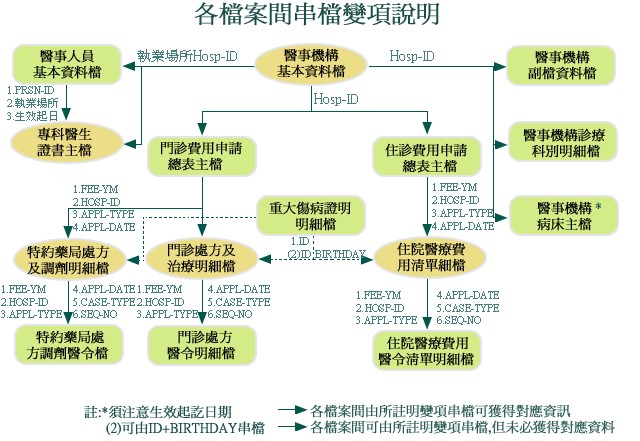
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖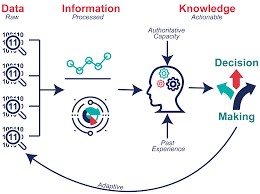

教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk

計畫撰寫與統計諮詢


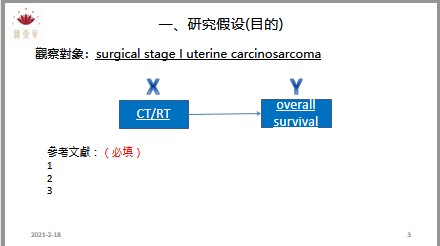
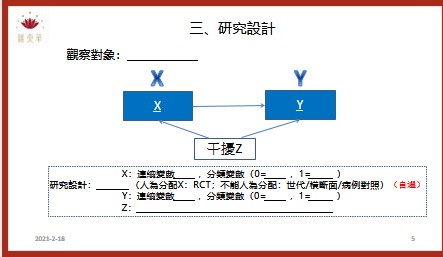
為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。