![]() 匯東華統計顧問有限公司
匯東華統計顧問有限公司
"匯東華-認真作好每件事"
~統計,不再是阻力,而是助力~

BMJ小小統計問題(150):Pitfalls of statistical hypothesis testing: multiple testing (統計假設檢定的陷阱:多重檢定)
前言
在科學研究中,尤其是醫學研究中,進行多重假設檢定是常見的做法。然而,多重檢定會增加型I錯誤(Type I error)的風險,即錯誤地拒絕虛無假設(Null hypothesis)的機率。本文探討多重假設檢定會遇到的問題及常用的校正方法,Bonferroni校正,更詳細的介紹可見BMJ(147),有對其應用和效果進行詳細說明。值得一讀。本問題也會見於投稿委員所提。因此,在進行多重檢定時,研究者需要意識到I型錯誤率膨脹的問題,謹慎解釋結果,並考慮使用適當的校正方法來控制整體的錯誤率,以提高研究結果的可靠性和可重複性。
相關主題:
#第8題:瞭解統計假設檢定 (Understanding statistical hypothesis testing)
#第27題:縱貫性研究之分析(Analysis of longitudinal studies)
#第30題:多重顯著性檢定 (Multiple significance tests)
#第31題:多重顯著性檢定:the Bonferroni correction (Multiple significance tests: the Bonferroni correction)
#第147題:Multiple hypothesis testing and Bonferroni's correction
匯東華三周年慶典:擁抱AI,引領研究新紀元!
親愛的學友們,
匯東華陪伴大家走過三個豐碩年頭,正值AI數智時代來臨之際,我們準備好迎接研究生態的革命性變化了嗎?
重磅推出:AI應用於科學研究系列課程
第一期7月6日(六)-7日(日),圓滿結束,感謝線下與線上學員的參與與滿滿的好評!課程詳細介紹可見課程報名區。
- #第二期 9/21 (六) AI03: 使用ChatGPT助力文獻綜述—建立自己的學術GPTs
- #第二期 9/22(日)AI04: ChatGPT助力統計分析與資料視覺化
我們的目標:善用AI工具,擺脫耗時費力的研究瑣事,讓您專注於研究本質,釋放無限創造力!
三周年特別福利
- 限時優惠:https://pse.is/65bzf2
- 會員專屬權益: https://pse.is/65bzhq
更多學習資源:
- BMJ統計問題列表: 匯東華官網/學習專區
- 線上課程: https://medata.teaches.cc/
想了解更多?
- 最新消息: https://reurl.cc/n1MGyv
- 課程詳情與報名: https://reurl.cc/EoRxpg
立即行動! 聯繫我們的官方LINE: @medatatw,感謝您一路相伴,讓我們一同在AI時代展翅高飛! ✨
問題:
本研究調查家庭介入對兩歲兒童身體質量指數(BMI)的影響。採用隨機對照優效試驗。介入措施包括由受過專門培訓的社區護士在兒童出生後 24 個月內進行八次家訪。介入目的為改善父母和兒童的健康和福祉。介入措施是對社區衛生服務護士提供的常規兒童護理服務的補充。對照組只接受常規的兒童護理服務。參與者為初為人母的母親及其嬰兒[1]。
主要結局指標是兒童兩歲時的身體評估指標,包括BMI、體重和身長。次要結局包括八項飲食行為測量和四項體能活動測量,以及兒童兩歲時看電視的情況。其中包括飲食習慣(水果和蔬菜的攝入量、薯片和零食的攝入量)、在電視機前用餐、看電視的時間以及積極玩耍的時間。次要結局還包括對母親產後 24 個月的飲食行為、看電視時間和體能活動的七項測量。
結果發現,介入組 2 歲時的平均BMI明顯低於對照組(P=0.04)。與對照組相比,介入組兒童在出生後 24 個月的飲食行為和看電視情況有明顯差異。介入組兒童吃了更多蔬菜(P=0.03),而把食物作為獎勵(P=0.03)、吃飯時開著電視(P=0.02)、在電視機前吃晚飯(P=0.01)和每天看電視超過 60 分鐘(P=0.02)等行為在介入組中都較少。兩組母親的飲食行為和體能鍛煉特點也存在明顯差異。介入組的母親吃更多的蔬菜(P<0.001),吃更少的加工肉類(P=0.03),更經常鍛煉身體(P=0.04)。
下列敘述何者正確?(複選)
a) 若母群體中 2 歲時治療組之間的平均BMI沒有差異,則會出現型 I 錯誤
b) 每個統計假設檢定之型 I 錯誤率為 5%
c) 多重統計假設檢定的型 I 錯誤率為 5%
答案
a 和 b 正確,c 錯誤。
詳細說明:
該試驗旨在調查家庭介入對兩歲兒童BMI的影響。該試驗是一項隨機對照試驗研究。研究結果包括兒童 2 歲時的BMI、體重和身長,以及兒童和母親出生 24 個月後的飲食行為和體能鍛煉情況。研究採用優效試驗研究設計[2]。目的為確定介入對體重和飲食行為的影響是否優於對照組,或者對照組是否比介入更有效。研究人員採用傳統的統計假設檢定方法[3]來檢定介入效果是否優於對照組,並提出虛無假設和對立假設。
研究人員進行多重統計假設檢定。針對所述結果指標進行 24 次檢定。假設檢定 P 值的推導為基於無限次抽樣的理論情況 [4]。對於每種結果,都將從首次接受介入之母親及其嬰兒母群體中進行抽樣,並假定介入治療與對照治療間不存在差異。每次抽取的樣本大小相同,並在相同的條件下獲得。假設檢定的 P 值是指,若按照虛無假設的規定,母群中各治療組間在結果測量上不存在差異,那麼各治療組間在結果測量上出現觀察到的差異(或更大差異)的機率。每個假設檢定的顯著性臨界水準定為 0.05(5%)。因此,對於每種結果,在這些樣本中,有 5%的樣本會拒絕虛無假設,而選擇對立假設。特別是,這 5%的樣本將是在結果測量中顯示治療組間差異最大的樣本,無論介入組的結果是大於或是小於對照組。
假設檢定的目的是根據樣本對母群體進行推定。然而,這種推定有可能無法代表母群體。假設檢定時可能會出現兩種類型的誤差—型 I 誤差和 型 II 誤差 [5]。若假設檢定的結果否定虛無假設,而支持對立假設,但母群體中的治療組間並不存在差異,則結果測量為出現型 I 誤差。例如,在上述研究中,發現治療組間 2 歲時的平均BMI存在顯著差異(P=0.04)。但是,若治療組間 2 歲時的平均BMI在母群體中不存在差異,就會出現型 I 錯誤(a 正確)。這種錯誤可能來自抽樣誤差[6]。
若假設檢定的結果為,當母群體中的治療組間存在差異時,沒有否定虛無假設而支持對立假設,則結果就會出現型 II 錯誤。但在假設檢定後,並無法確定發生的是哪一型錯誤。
如上所述,對於每次統計假設檢定,從母群體中隨機抽取的樣本中,有 5%的樣本會拒絕虛無假設,而選擇對立假設。因此,對於任何一次假設檢定,拒絕虛無假設的最大機率為 0.05(5%)。任何假設檢定都可能導致 I 型錯誤。因此,I 型錯誤的最大機率是 0.05(5%)。此被稱為型 I 錯誤率(b 正確)。
在進行多重假設檢定時,隨著檢定次數的增加,治療組間出現顯著差異的機率也會增加,因此出現型 I 錯誤的機率也會增加,會大於 0.05(5%)。例如,當有兩個、三個和四個假設檢定時,出現顯著結果的機率分別為 0.098、0.143、0.186 和 0.226。很明顯,型 I 錯誤率將大大高於 5%。因為多重統計假設檢定的整體型 I 錯誤率隨著檢定次數的增加而增加。(c 錯誤),令人無法接受。這些機率假定假設檢定是獨立的,即結果是相互獨立的。然而,對於上述研究來說,這是不可能的。例如,孩子們在吃飯時間看電視、在電視機前吃晚飯以及每天看電視超過 60 分鐘的結果並不是獨立的—若其中一個結果出現,其他結果也很可能出現。若結果並非獨立的,則多重假設檢定後得出顯著結果的機率就會進一步增加,並且會比上述結果更大。
在本例研究中,共確定 24 項結果測量。當研究論文進行大量統計檢定時,必須小心謹慎--其中一些檢定最終會導致型 I 型錯誤。然而,我們無法確定哪些重要結果屬於型 I 錯誤。在進行多重檢定時,學者提出各種方法來控制型 I 錯誤率。最簡單的方法是 Bonferroni 法。此方法是用傳統的 0.05 臨界顯著性水準除以所進行的顯著性檢定次數,得到一個新的臨界顯著性水準。該方法的缺點是傾向於保守,即偏向於不顯著。不過,它確實避免虛假的顯著結果。
Reference
[1] Wen LM, Baur LA, Simpson JM, Rissel C, Wardle K, Flood VM. Effectiveness of home based early intervention on children’s BMI at age 2: randomised controlled trial. BMJ 2012;344:e3732.
[2] Sedgwick P. What is a superiority trial? BMJ 2013;347:f5420.
[3] Sedgwick P. Understanding statistical hypothesis testing. BMJ 2014;348:g3557.
[4] Sedgwick P. Understanding P values. BMJ 2014;349:g4550.
[5] Sedgwick P. Pitfalls of statistical hypothesis testing: type I and type II errors. BMJ 2014;349:g4287.
[6] Sedgwick P. What is sampling error? BMJ 2012;344:e4285.
#匯東華 #BMJ統計問題 #醫學統計 #ANOVA #Bonferroni test #事後檢定 # Multiple hypothesis testing #Type I error #Type II error

數據串接與清洗
數據是礦藏,數據清洗是挖出鑽石的第一步,尤其是巨量知識。數據清洗或串接執行過程需要細心與專注,且有可能會消耗許多時間和精力,就由我們來替各位處理掉這個大麻煩。
全民健保研究資料庫、國外大型資料庫資料非常齊全,種類多,需要串接與清洗,進行正規化後才能更進一步進行資料探勘與統計分析。

Fig1.同一個Project資料散落在不同tables,無法使用
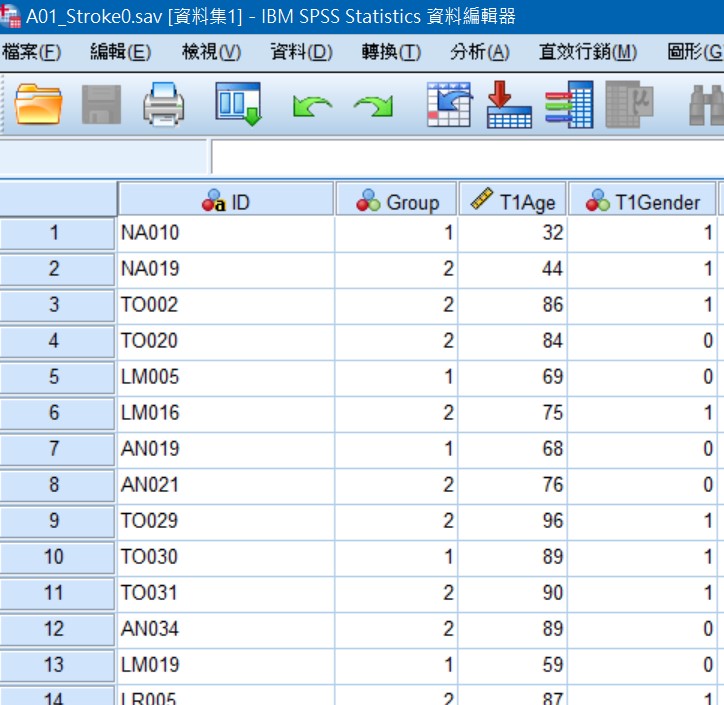
Fig2.整併與清理為可分析的table
Fig.3整理和分析後形成有意義的知識
概念與流程示意圖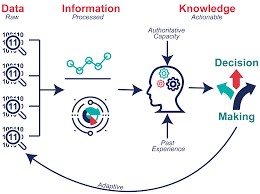

教育培訓
課程規劃核心為以「學習者」為中心進行「傳承」
以學習者為中心,結合陳秀敏博士十多年來的統計實務以及教學經驗,設計適合學員學習方式,開設課程,達到有效學習。
開設線上統計學院
SPSS基礎統計實戰班:第一次分析SCI研究就上手(上、下)
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=MPz2wqN0v2M
課程介紹2:https://www.youtube.com/watch?v=nd5A5duxO5E
臨床研究思維-Open your mind
課程網址:https://medata.teaches.cc/
課程介紹1:https://www.youtube.com/watch?v=yTHdBnCdSnY
課程介紹2 : https://www.youtube.com/watch?v=kE9tXraICqk

計畫撰寫與統計諮詢


為了讓匯東華的顧客與學員有更好的合作和消費體驗,故匯東華特別依據營業項目開發周邊產品,提供使用、購買。目前已有針對公共衛生師的題庫以及模擬試題,未來將針對醫學研究領域發展產品。